JSON Schema is a constraint system
Or: Why object-oriented programming is a mis-matched mental model for JSON Schema

I am a software engineer, REST API enthusiast, co-author of the JSON Schema, and occasional interactive theatre performer.
Did you come to JSON Schema with an object-oriented programming (OOP) background? Do think of writing a schema as analogous to writing a class? These expectations are both common and understandable, but incorrect.
In this article, you'll learn:
What it means for JSON Schema to be a constraint system
How to think about designing constraints effectively
Why "constraint" encompasses more than just JSON Schema assertions
Constraints vs Definitions
This is an empty schema (in all versions1 of JSON Schema):
{}
It allows everything.
This is an empty class in Java:
public class Empty {
}
It does nothing.
Building Java classes and JSON Schemas for a data model work from opposite starting points and require different approaches:
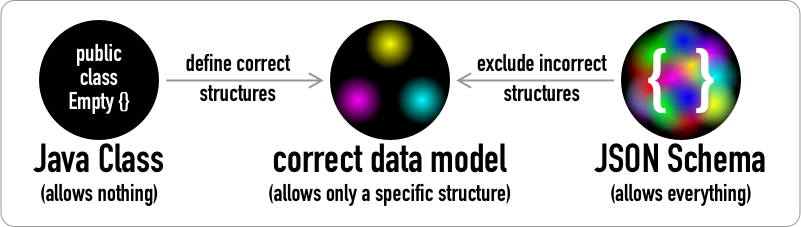
Class definition systems are additive: You start from nothing and the more you specify, the more you can do. On the left, our empty Java class is a black disc with no other colors. You add fields to define the correct set of possible data.
Constraint systems are subtractive: You start with everything and the more you specify, the less you can do. On the right, our empty JSON Schema is a black disc covered by a chaotic riot of color blobs. You add keywords to exclude all incorrect data. This thought process runs in the opposite direction compared to defining a class in Java.
Both processes converge in the middle, where our correct data model is shown as three colors at the points of an equilateral triangle on a black disc. So let's look at how these different processes work.
Be forbidding!
If we were thinking about Java classes and JSON Schemas in parallel, our next step might be adding a property to each (using a single public boolean data attribute for simplicity — colors and shapes just made a better visual!)
public class Empty {
public boolean isOn;
}
{
"properties": {
"isOn": {
"type": "boolean"
}
}
}
While these look analogous, they are very different. Constraints in JSON Schema constrain as little as possible. This maximizes flexibility for schema authors. All this schema says is "if the instance is an object, and if it has a property named isOn, then that property must be a boolean."
In contrast, Java classes are inherently objects with named fields. Java classes only have the fields you declare. They always have those fields, even if you don't use them. The fields are initialized automatically, which for booleans means being set to false.
That's four additional constraints that we need to add to our JSON Schema (using JavaScript comment syntax):
{
"type": "object", // forbid non-objects
"required": ["isOn"], // forbid objects without "isOn"
"properties": {
"isOn": {
"type": "boolean", // forbid non-boolean "isOn"
"default": false // forbid assuming "isOn" is true
}
},
"additionalProperties": false // forbid props that aren't "isOn"
}
This might seem strange. Why would you want to consider a non-object valid if you are describing object properties?
When you're writing a Java class, you are starting with Java's inherent concept of a class, with all of its automatic behaviors (such as attribute initialization) and assumptions (classes always having exactly the set of attributes that were declared, no more, no less). Java knows that you only want the things you say you want.
On the other hand, JSON Schema has no idea what you're trying to do and can't make any assumptions for you. It doesn't know that you're trying to match an OOP language. Even if it did, you could be writing in Perl, where a reference to anything, even a number or string, can be "blessed" as a class instance and properties can be added or removed at any time.
This is why JSON Schema is a constraint system, and why you want to understand that instead of trying to use as if it were something else.2 It has to work with anything that might be done in JSON, and it relies on you to ask yourself, "have I forbidden everything I don't want?"
Constraints vs validation assertions
JSON Schema has different keyword behaviors including assertions, which can cause validation to fail, and annotations, which can't fail validation but do provide additional information about valid instances.
All of the JSON Schema keywords in the example above are assertions except "default", which is an annotation. But if you're using this schema for code generation, "default" is a constraint in that context. A "default" of true would require a generated Java class to initialize isOn to true. Non-assertions can be constraints in non-validation use cases!
Conclusion
In this article, you've learned that:
JSON Schema is a constraint system because it can't know how you will use it
Java and similar languages know how you will use them, and make assumptions accordingly
The empty JSON Schema allows everything
The schema design mindset is: "Have I forbidden everything I don't want?"
Whether a keyword functions as a constraint depends on how you are using the schema
Please let me know what you think in the comments, and please click the "Follow" button so you don't miss the next two posts: First, an explanation of dynamic scopes, which you'll want to understand so you get the most out of the following post: When to use "additionalProperties" vs "unevaluatedProperties"!
In real-world usage, you should always specify
"$schema", as different implementations handle its absence differently. Some assume a default version (which might not be the one you expected), and others won't process such schemas at all because they don't want to risk giving an incorrect validation outcome with an inaccurate default assumption. To keep examples more readable, I'll often omit"$schema"when it doesn't change how the example is understood. ↩There have been some misguided attempts to reconcile OOP and constraints. For example, recent versions of the popular AJV implementation of JSON Schema set a bunch of "strict mode" options by default. Many of these attempt to make JSON Schema behave more like a data definition system, but the resulting behavior is not compliant with the JSON Schema specification. In a future article, we'll look at when it is useful to use AJV's strict mode, and when it is problematic. While AJV's strict mode prevents certain valid schemas from being used rather than changing their outcome, this breaks interoperability as many things it prevents have valid use cases. Such schemas written for use with compliant implementations will fail with AJV, which is why the JSON Schema implementations page now notes implementations with noncompliant default behavior. ↩