
Analyzing the OpenAPI Tooling Ecosystem
OpenAPI Deep Dive Diagrams, Part 1: Looking at tasks rather than tools
H
I am a software engineer, REST API enthusiast, co-author of the JSON Schema, and occasional interactive theatre performer.
Search for a command to run...
OpenAPI Deep Dive Diagrams, Part 1: Looking at tasks rather than tools
I am a software engineer, REST API enthusiast, co-author of the JSON Schema, and occasional interactive theatre performer.
Entrusting one's hard-earned money to the wrong hands can have devastating consequences. My journey began innocently enough, sparked by the success story of a former coworker who boasted of her newfound wealth and attributed it to the guidance of an investment coach. Intrigued by her lavish lifestyle, I delved deeper into the world of stock trading, eager to replicate her success. Upon contacting the purported investment coach, John Mark, I was met with promises of quick riches and convenient trading platforms. Eager to seize the opportunity, I followed his recommendations and funded my trading account with a significant sum of $78,000. However, what followed was a series of red flags and suspicious transactions that left me questioning the legitimacy of the entire operation. Despite completing numerous trades within my first week, attempts to withdraw my profits were met with resistance and dubious excuses. The company insisted on additional fees for gas and maintenance, a requirement that had never been mentioned before. As doubts gnawed at my conscience, I realized I had fallen victim to a sophisticated scam, orchestrated by individuals preying on unsuspecting investors. Feeling helpless and betrayed, I turned to FAST SWIFT CYBER SERVICES., a beacon of hope amidst the chaos. From the moment I reached out to them, their team exhibited understanding the gravity of my situation. They conducted a thorough investigation, meticulously analyzing every aspect of the scam to uncover the truth. FAST SWIFT CYBER SERVICES. technical expertise are experienced .Despite the complexity of the case, they remained steadfast in their pursuit of justice, leaving no stone unturned in their quest to reclaim what was rightfully mine. With the information I provided, FAST SWIFT CYBER SERVICES. successfully traced the origins of the scam and identified the culprits responsible for my financial misfortune. Their swift action and relentless determination culminated in the recovery of all lost funds, restoring my faith in humanity and the promise of a brighter future. The amount recovered, totaling $78,000, served as a testament to FAST SWIFT CYBER SERVICES.'s unparalleled capabilities and unwavering commitment to ethical practices. Their transparency and willingness to explain their procedures instilled a sense of trust, which was crucial during such a trying time. I cannot recommend FAST SWIFT CYBER SERVICES. highly enough to anyone who finds themselves ensnared in the clutches of financial fraud. Their exceptional service is good. If you ever find yourself facing a similar ordeal, don't hesitate to seek help from FAST SWIFT CYBER SERVICES.. Let FAST SWIFT CYBER SERVICES. be your savior. Contact FAST SWIFT CYBER SERVICES. via⁚ Email: fastswift @ cyberservices . com Telephone: +1 323-904-9024 WhatsApp: +4670-449-7301
When faced with the distressing reality of falling victim to a financial scam, seeking guidance and assistance from reputable recovery services becomes paramount. fast swift cyber services as help in such dire situations, offering expert support and expertise to individuals grappling with the aftermath of fraudulent schemes. The journey of recovery often begins with a seemingly innocuous interaction, as was the case for many who have sought assistance from fast swift cyber services. A message on Twitter, an initial expression of interest, and the gradual establishment of a relationship pave the way for unsuspecting individuals to be drawn into the intricate web of deception. In my review, the tale unfolds with the promise of quick riches through 30-second trades on a dubious platform. A modest investment of USD 49,000 snowballs into a significant sum, further fueled by persuasion to inject additional funds amounting to £61,000 in ETH.
The allure of exponential growth through completing routine tasks blinds many to the looming danger lurking beneath the surface. However, the facade of prosperity quickly crumbles when attempts to withdraw profits are met with inexplicable obstacles. A withdrawal failure serves as the first ominous sign, followed by a cascade of demands from the supposed support team. The requirement to pay exorbitant trading fees to access one's funds becomes a seemingly insurmountable barrier, with promises of resolution serving only to deepen the despair. Prompt action is taken to reach out to this trusted ally, and the response is nothing short of miraculous. Within days, the team at FAST SWIFT CYBER SERVICES embarks on a mission to trace and recover the lost funds, culminating in a swift resolution that defies all odds.
The efficiency and professionalism displayed throughout the process serve as a testament to the unwavering dedication of FAST SWIFT CYBER SERVICES to their clients' cause. Beyond the tangible outcome of fund recovery, the experience instills valuable lessons about the importance of due diligence and vigilance in the realm of online investments. Scammers prey on vulnerability and trust, exploiting unsuspecting individuals with promises of unrealistic returns. However, armed with knowledge and awareness, individuals can fortify themselves against such deceitful tactics, ensuring that they approach investment opportunities with caution. In addition to seeking professional assistance, proactive steps are taken to protect oneself from future scams. Education becomes a powerful tool in the arsenal against fraud, empowering individuals to recognize and avoid potential pitfalls before they fall victim. By sharing personal experiences and advocating for awareness, individuals can play a pivotal role in preventing others from suffering a similar fate.
FAST SWIFT CYBER SERVICES emerges as a trusted ally in the fight against financial fraud, offering expert guidance and assistance to those in need. Through their unwavering commitment to justice and integrity, they provide a lifeline to individuals grappling with the aftermath of fraudulent schemes. With their support and a renewed sense of vigilance, individuals can navigate the online landscape with confidence, safeguarding their financial well-being and protecting themselves from future scams. Reach out to them on;
HIRE FAST SWIFT CYBER SERVICES TO RECOVER YOUR LOST OR STOLEN BITCOIN/ETH/USDT/NFT AND OTHER CRYPTOCURRENCY
Email: fastswift @ cyberservices . com Telephone: +1 323-904-9024 WhatsApp: +4670-449-7301
Part 1: Component re-use and the OpenAPI road map
New OpenAPI and JSON Schema work for 2024!

Or: Why object-oriented programming is a mis-matched mental model for JSON Schema

Welcome to the Modern JSON Schema (& APIs) blog! My name is Henry, and I'm the H. Andrews who co-authored all drafts of JSON Schema from 2017 to the present. With this blog, I want to help you use JSON Schema to the full extent of its capabilities!...

Welcome to a new series of posts that will take you on a visual journey through the OpenAPI Specification (OAS) and its tooling ecosystem!
As part of the efforts to design OAS 3.2 and 4.0 “Moonwalk”, I wanted to figure out how different sorts of tools work with the OAS. Moonwalk is an opportunity to re-think everything, and I want that re-thinking to make it easier to design, implement and maintain tools. We also want 3.2 to be an incremental step towards Moonwalk, so figuring out what improvements we can make to align with the needs of tools while maintaining strict compatibility with OAS 3.1 is also important.
To do that, we need to understand how the OAS-based tooling ecosystem works, and how the various tools relate to the current OAS version, 3.1. This eventually led me to create two groups of diagrams: One about the architecture of OAS-based tools, and one about the many objects and fields defined by the OAS and how they relate to what tools need to do. But this was not a simple process!
I was surprised at how difficult it was to find patterns in tool design and OAS usage. I thought I could go look at how tools were categorized on sites that list them, figure out what each category needs, and see how that aligns with the current and proposed future OAS versions. I was wrong. Looking the OpenAPI Initiative’s own tools site reveals categories that often overlap and tools that don’t map cleanly to categories.
One problem is that many “tools” aren’t so much OAS implementations as they are applications that include some OAS-based functionality. So maybe “tool” or “application” isn’t the right granularity for this research. Really, there are different tasks that can be done with an OpenAPI Description (OAD), and each OAS-based tool, application, or library does at least one such task.

I started thinking about all of the tasks, and how they relate to each other. The goal is not to really create a monolithic mega-tool architecture. Not all tasks happen on the same system, or at the same time in the development process. But it would help to understand which tasks directly relate to each other, which don’t, and what the interfaces among them ought to be.
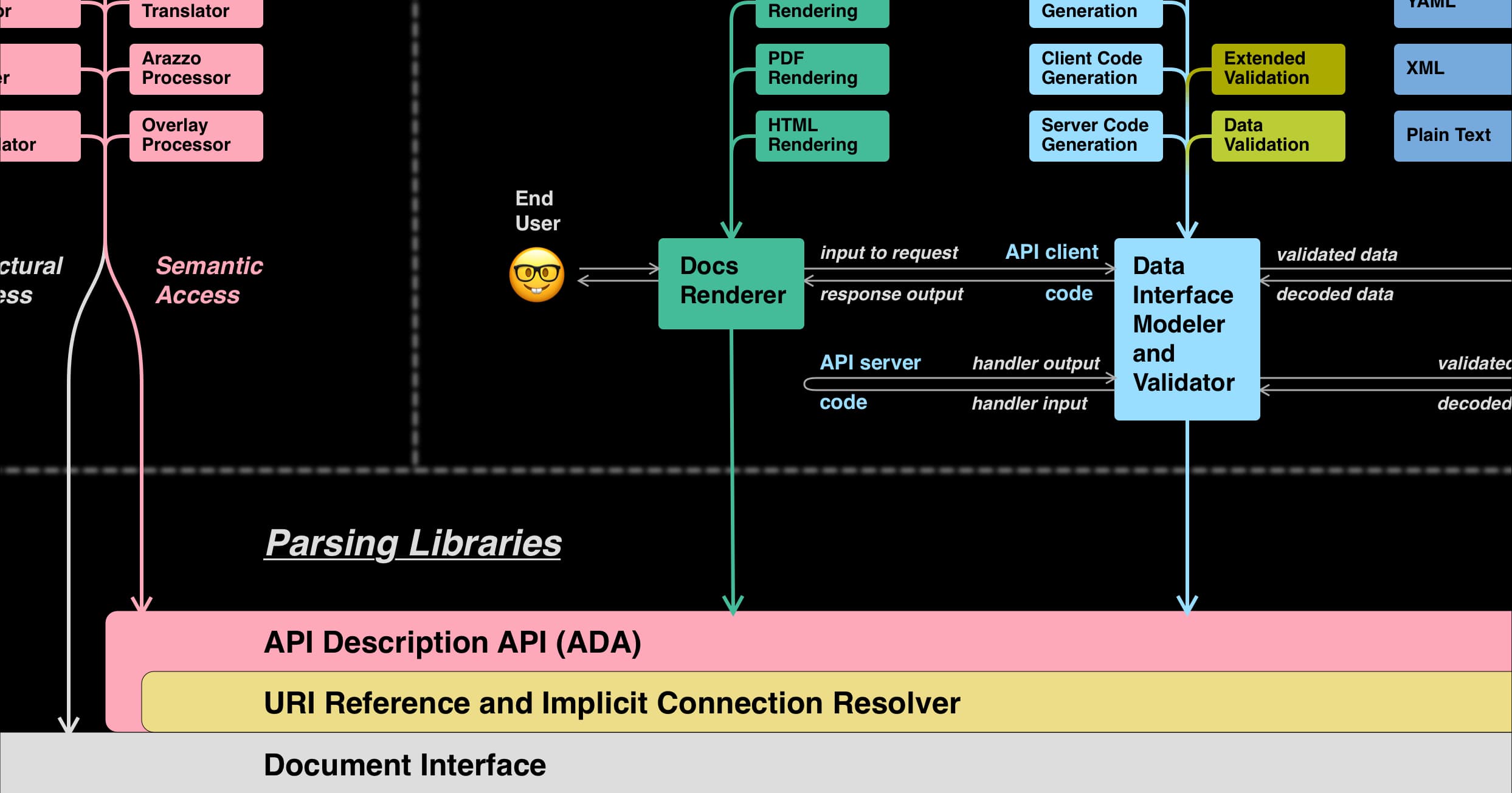
After several iterations with valuable feedback from the regular OAS working group calls, here is what I came up with (based on OAS 3.1 plus ideas for 3.2 and Moonwalk):
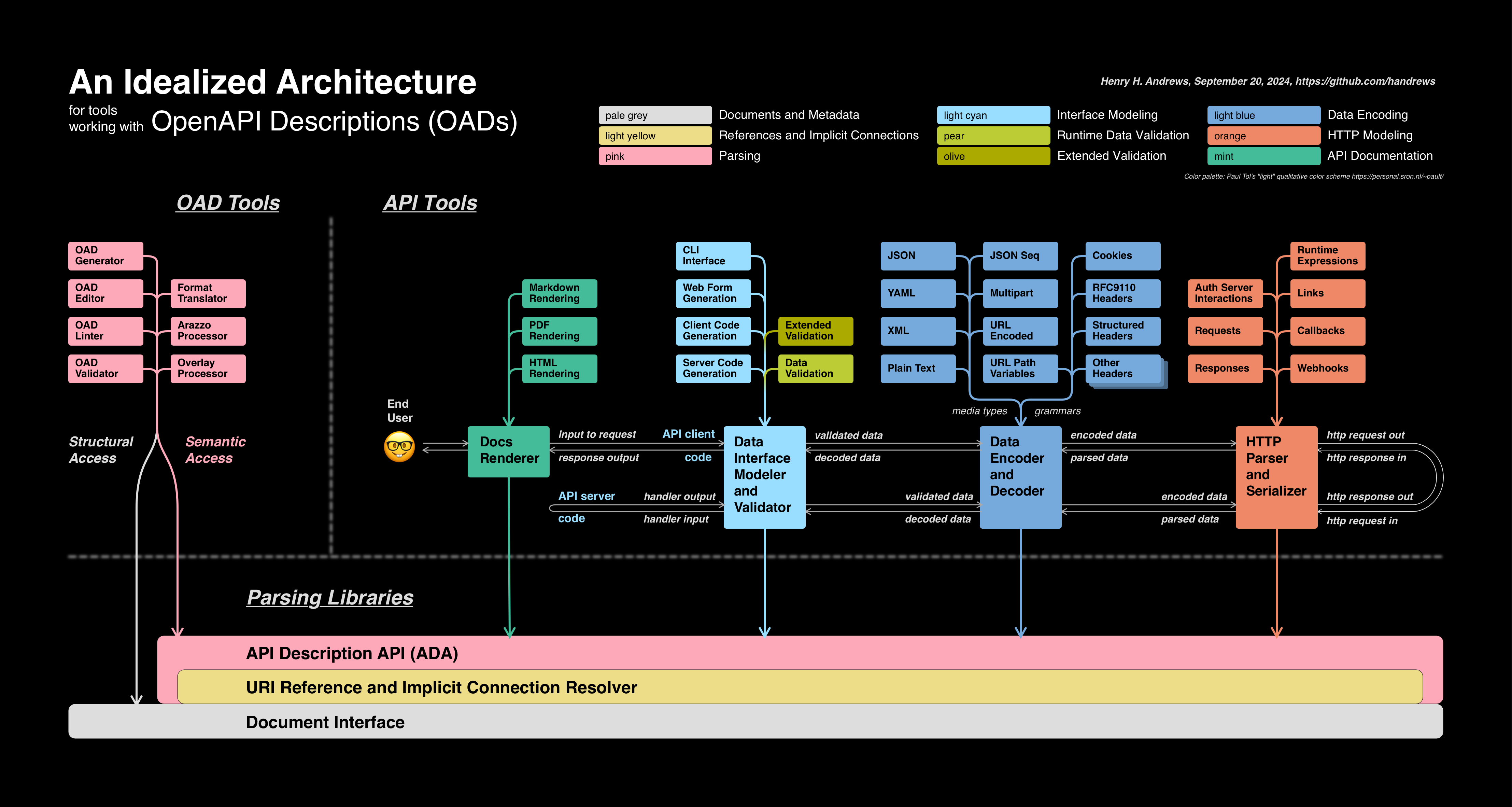
The first thing to notice is the that this “idealized architecture” breaks down into three main purposes or functional areas:
Parsing libraries: The foundation on which all other tools are built
OAD tools: These work with OpenAPI Descriptions and their constituent documents
API tools: These work with the API that the OAD describes but (mostly) aren’t concerned with the mechanics of OAD documents and references
Before we look at the three purposes, let’s talk about how I’m using color in these diagrams:

The colors here, named “pale grey”, “light yellow”, “pink”, “light cyan”, “pear”, “olive”, “light blue”, “orange”, and “mint”, are a set designed by Paul Tol to work well with dense grids of information labeled with black text, regardless of color vision ability.
I’ll always use these names (minus the “pale” and “light” qualifiers) to talk about the colors in these diagrams. Every diagram will include the color names so that no one has to guess which color is which, and all diagrams use the same colors to mean the same general things:
Gray: Documents and metadata
Yellow: References and implicit connections
Pink: Parsing
Cyan: Interface modeling
Pear: Runtime data validation
Olive: Extended validation
Blue: Data encoding
Orange: HTTP modeling
Mint: API documentation
As we compare diagrams about tools with diagrams about the spec (which you’ll see in future posts), we will hope that consistent use of color will show clear alignment between these two perspectives. Wherever they do not, we probably have some work to do.

The most fundamental functional area, “Parsing Libraries”, consists of a stack of wide blocks stretching across the bottom. From the color code, you can see that these blocks deal with the low-level document interface (grey), resolving references and implicit connections (yellow), and parsing (pink). “Implicit connections” is a term we’re introducing in OAS 3.0.4 and 3.1.1 that encompasses things like mapping Security Requirement Object keys to Security Scheme Object names under the securitySchemes field of the Components Object.
Every tool, application, or library that works with OADs or the APIs that they describe has to parse OADs and do at least some resolution of internal connections. While some references can be preprocessed out, others cannot, nor can any of the implicit connections. We’ll explore these challenges, as well as the interactions between the grey, yellow, and pink blocks, more deeply in future posts.
For now, the most important thing is that the upper pink block, which I’m tentatively calling the “API Description API (ADA)”, is intended to provide a clean interface to the parsed and resolved OAD that insulates tools from the complexities of document managing and referencing. This ADA would be somewhat akin to the DOM. There are, however, fundamental differences between OADs and web pages, so the analogy is not exact.
We’ve decided that we want to have an ADA in Moonwalk. It’s an open question as to whether it would be worthwhile to start defining it in 3.x. Would 3.x tools (or at least parsing libraries) would start supporting it? If you have thoughts on that concern, or on whether “ADA” is a good name, we’d like to hear from you!
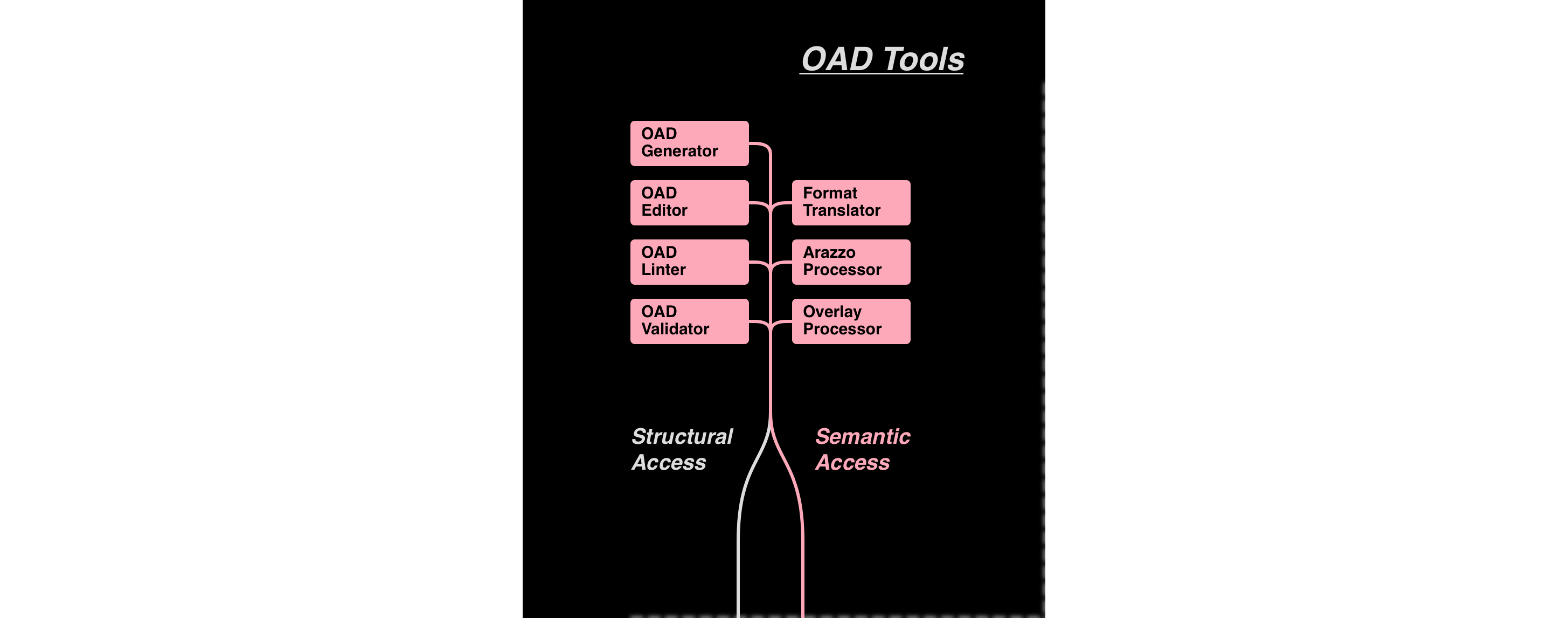
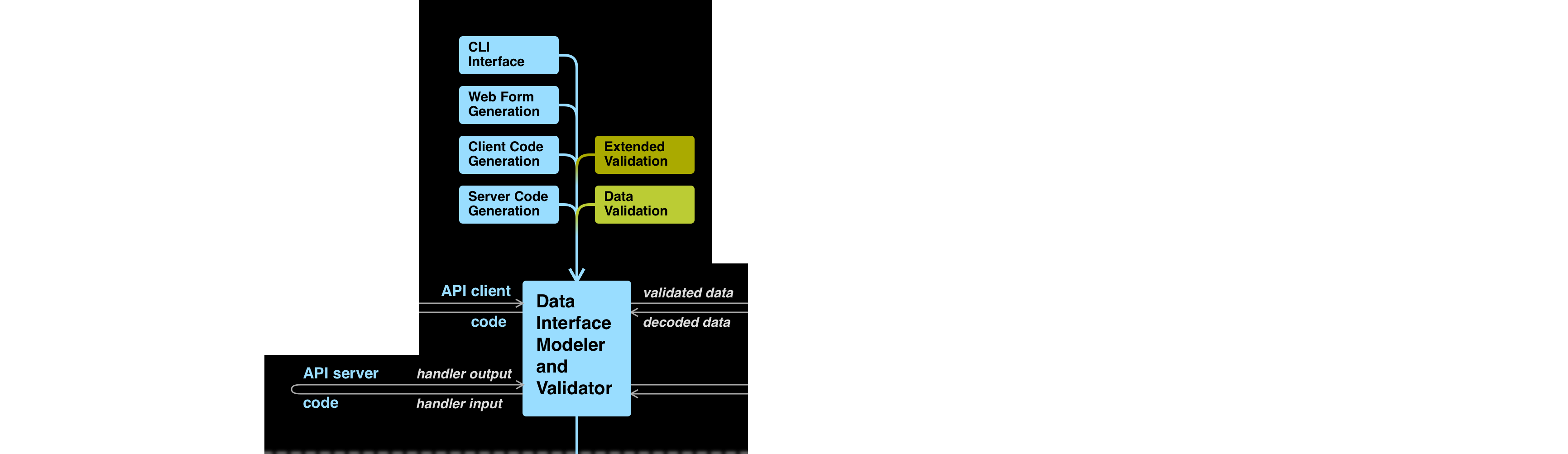
The first change I would make to sites that classify OpenAPI tools would be to separate the tools that work with OADs from the tools the work with APIs.
These are fundamentally different use cases and mindsets, and they have different requirements when it comes to interacting with OADs. The blocks in this area are colored pink because they are primarily concerned with the structure of the OAD. The description semantics inform what can or should be done with the OAD, but it is the OAD rather than the described API that is the focus of these tools.
The left column includes OAD editors (including IDE plugins), validators, linters, and generators (producing an OAD from code). The right column includes tools connecting the OAD with other specifications, including the OpenAPI Initiative’s Arazzo and (forthcoming) Overlays specifications. The right column also contains translators from other formats such as RAML, or from formats that offer an alternative syntax that “compiles” down to an OAD.
Semantic operations, such as a linting rule that applies to every Response Object, no matter its location, benefit from semantic access via the ADA (pink downward arrow). Structural operations, such as an overlay that inserts a field into each object matching a JSON Path applied to a specific document (or anything that requires writing to documents), benefit from structural access via the underlying document interface (grey downward arrow).
Now that we’ve accounted for shared parsing tasks and OAD-specific tools, we’re ready to examine how the OAS supports working with an API. We’ll start on the left edge where our hypothetical end user is looking at an interactive documentation site that includes a test interface to send requests and display the resulting responses.
While our discussion will follow the progress of a request on the client side, the steps are reversed to parse, decode, and validate the request on the server, and then run again on the server to validate, encode, and assemble a response, which is parsed, decoded, validated, and displayed to the end user on the client side.

Documentation is produce by mint-colored blocks that use the ADA to walk through the whole OAD, organize the information for human consumption, and render it to the end user in some format. Different formats could be handled as plugins in an extensible architecture, as shown above the main mint-colored block.
The API documentation block is the only one that looks at every part of the OAD that is visible through the ADA. Separating docs processing into its own block allows other blocks to ignore the fields that only impact documentation. This might influence how the ADA is designed.
If the documentation is interactive, then it would incorporate an interface generated by the next block that can take the appropriate session or operation input and render the results. The mint blocks are concerned with rendering that interface, but not with defining it.
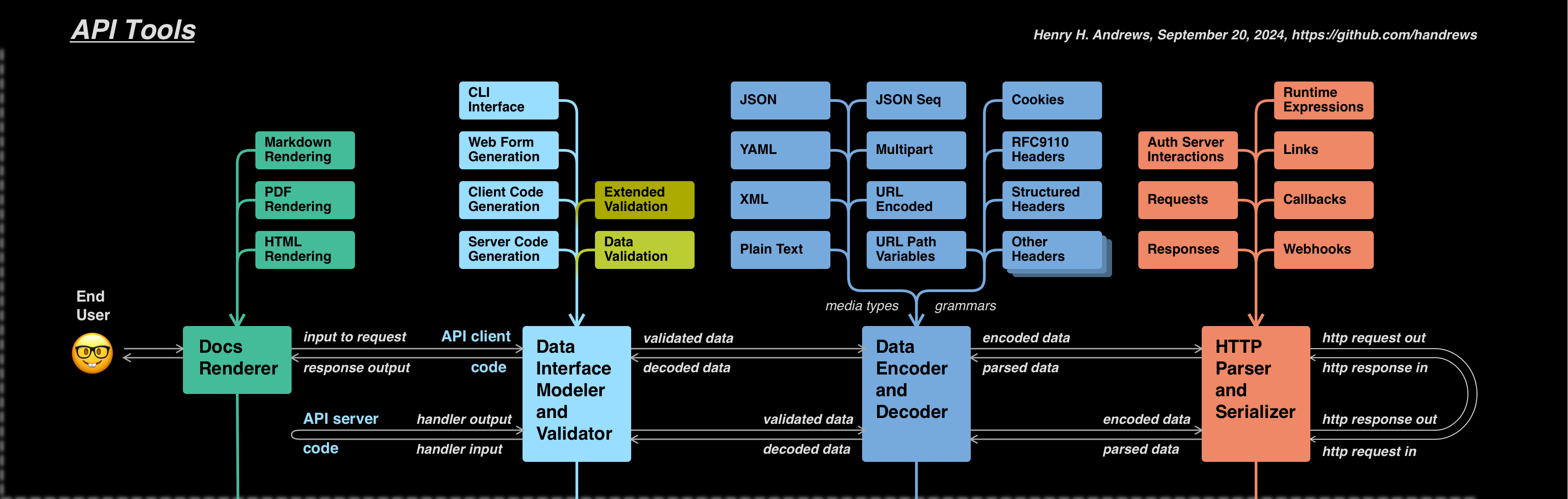
Following the arrow to the right, we reach the API client code. The boundary between the three differently-colored types of blocks within this larger area is somewhat ambiguous, and varies depending on the programming language(s) and types of tools being used.
Interface definition (cyan)
Cyan represents the static code-level (as opposed to HTTP-level) interface to the API. The diagram shows how there might be several form factors for this interface stacked in the left column above the main cyan block: Code libraries on the client and server, or a web or CLI interface for interactive documentation or manual testing. Such an interface might be very generic, or it might be custom-generated with elaborate static type-checking.
Runtime data validation (pear)
The pear-colored module is for runtime data validation, verifying constraints that are not inherent in the interface’s type-checking but only depend on the data passed to that interface. It's mostly synonymous with JSON Schema validation, although not entirely as we'll see when we color code individual fields in the next post.
Extended validation (olive)
The olive-colored module is for validation such as readOnly that requires additional context about how the data is being used, which often builds on the runtime validation by using annotations.
A confusing boundary
As noted, the boundary between these three colors is ambiguous. JSON Schema is not a data definition system, and was not designed with a clear division between static data types (cyan) and runtime constraints (pear) in mind. Languages support differing type-checking paradigms, tools have variable levels of support for classes or other complex structures, and "code generation" can be taken to the extreme of generating a custom function for each JSON Schema.
Additionally, format values are sometimes handled as static types (cyan), sometimes as runtime validation (pear), and sometimes as annotation-based validation (olive).
All of this overlap and ambiguity is a major challenge for tooling vendors, an one we’ll examine in detail in a future post.
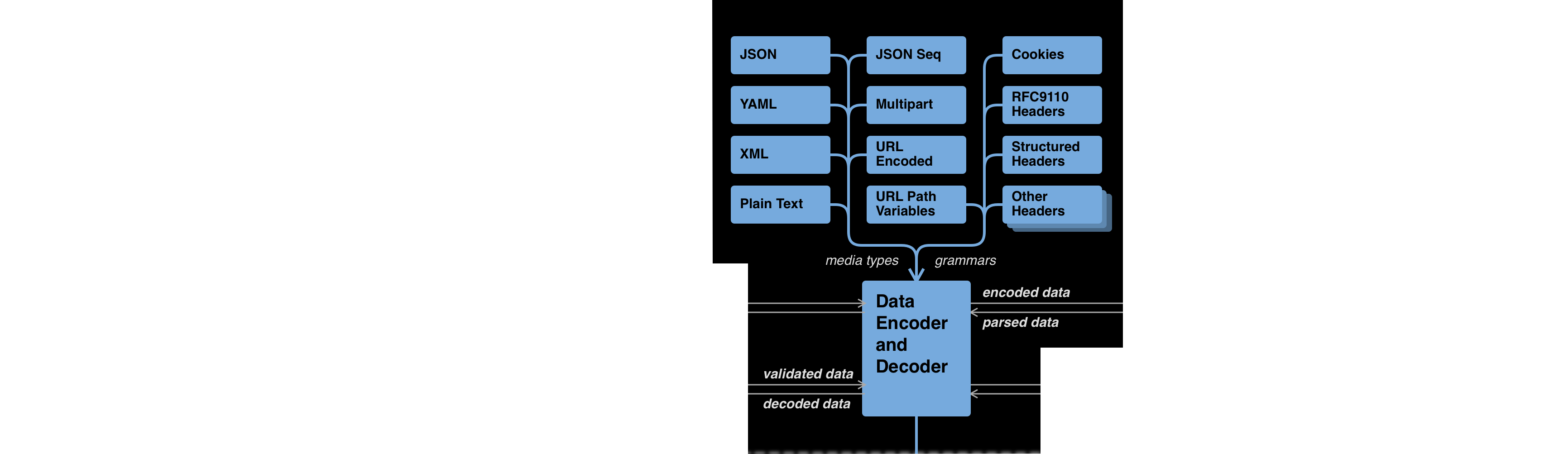
The code interface is defined in terms of JSON-compatible data structures. Encoding such a structure as an application/json request body is trivial. But validated data also needs to be mapped into other media types, and into various bits and pieces governed by other rules such as ABNF grammars.
In this diagram, I'm proposing a modular, extensible system to handle these encodings or translations. API innovation moves faster than specification development, and the OAS doesn’t currently have a good way to accommodate emerging data formats like JSON streams. We also haven’t ever addressed things like HTTP headers with complex structure.
Defining an extensible interface, where mappings to various targets could be defined in a registry and supported with a plug-in architecture, would dramatically increase the flexibility of the OAS tooling ecosystem, as well as its responsiveness to innovation. It could also help us get the substantial complexity of the data encoding fields, which we’ll start to explore in the next post, under control.

Finally, we reach the orange block that is takes the bits and pieces of encoded data and assembles them into HTTP messages (or parses them back out). We see on our diagram how data passes through this module as a request to be constructed, then back through on the server side where the request is parsed, handled, and returned as a response.
This area breaks down into three sub-areas: Server configuration (which provides the URL prefix for HTTP calls), security configuration (which might involve HTTP interactions with an auth server), and the actual API operations.
Much of this HTTP parsing and serialization can be handled by standard libraries, which can also help define us the exact border with the data encoding blocks. Our goal is to organize the OAS aspect of things, not to re-invent the wheel of HTTP and related technologies.
The next step is to analyze OAS 3.1 and the likely 3.2 proposals in detail and correlate the Objects and fields with this idealized architecture. That starts to show where we have mismatches between the spec and tools, and what we might want to do about them, which will be the subject of the next post.
However, one aspect of this diagram is already driving real work: This past week’s Moonwalk working group call featured a TSC member demo-ing a small ADA proof-of-concept. The idealized architecture may be theoretical, but its impacts on the future of the OAS are already very real.